Snowflake just turned an Iceberg implementation detail into a bill-owner decision.
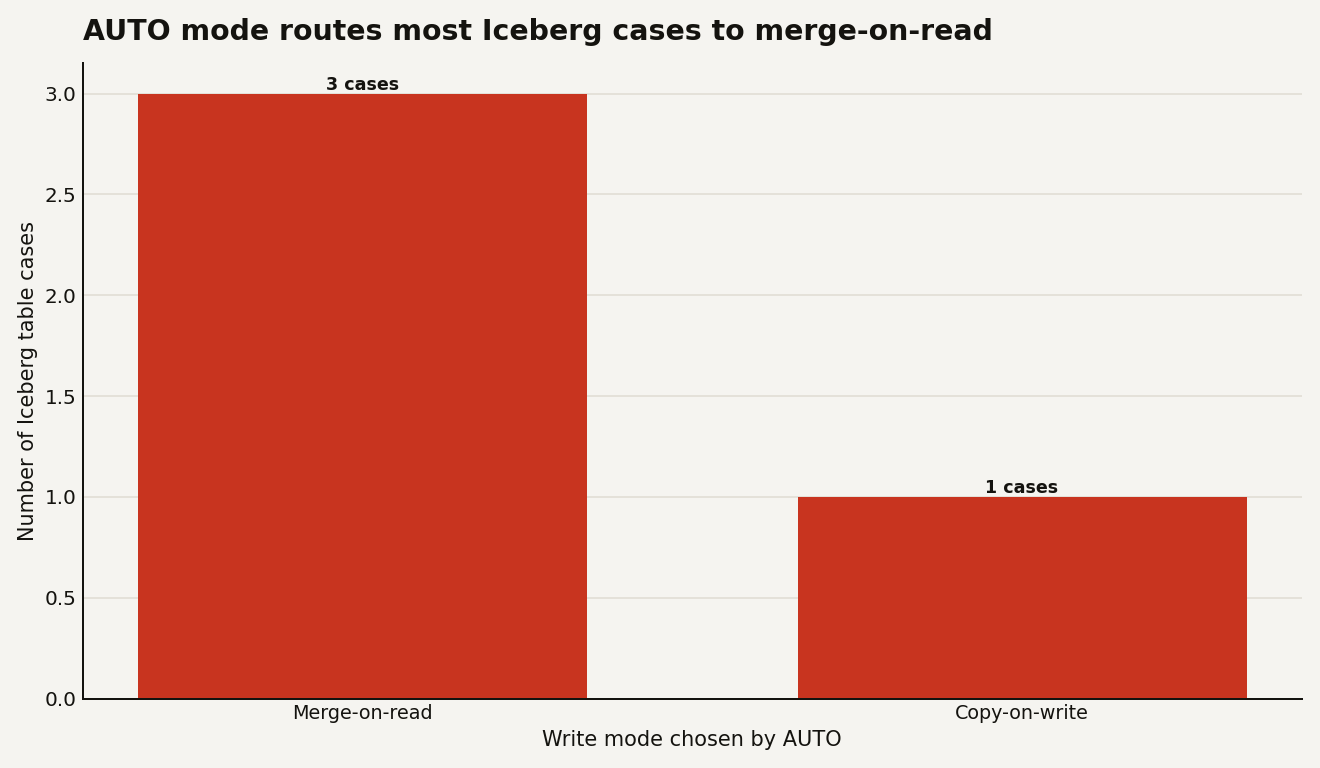
ICEBERG_MERGE_ON_READ_BEHAVIOR is the new general availability object parameter that controls whether Snowflake uses merge-on-read or copy-on-write for Iceberg UPDATE, DELETE, and MERGE. The key number is simple: under the default AUTO setting, 3 of 4 table cases use merge-on-read, while Snowflake-managed Iceberg v2 tables stay on copy-on-write unless you explicitly opt in.
That sounds small. It is not. For lakehouse teams, row-level DML is where the open-table dream usually meets the invoice. Copy-on-write rewrites whole data files. Merge-on-read writes delete files alongside the data and makes readers reconcile them later. One mode spends more during writes. The other can push work into reads and compaction. Snowflake's new parameter matters because it lets you choose that trade-off at the account, database, schema, or table level instead of letting it hide behind a legacy boolean.
If you are still sorting out where Iceberg belongs in your platform, start with our guide to putting your data lake in Snowflake Iceberg tables. This one is narrower: how this new switch works, how to audit it, and where it can move credits.
What did Snowflake actually ship for Iceberg DML?
Snowflake added a string parameter, ICEBERG_MERGE_ON_READ_BEHAVIOR, with three values: AUTO, ENABLED, and DISABLED. The 10.20 release notes say the parameter controls how Snowflake performs row-level updates on Apache Iceberg tables, specifically UPDATE, DELETE, and MERGE, by choosing between merge-on-read and copy-on-write in Snowflake-issued DML.
The default is AUTO. In that mode, Snowflake checks two things: the Iceberg format version and whether the table is Snowflake-managed or externally managed. Snowflake-managed v2 tables use copy-on-write. Snowflake-managed v3 tables use merge-on-read. Externally managed v2 and v3 tables use merge-on-read.
That gives you the 3 to 1 split shown below.
Snowflake's docs spell out the matrix in the row-level deletes guide. The vendor-safe read is obvious: AUTO protects Snowflake-managed v2 tables because external readers might not support v2 positional delete files. The builder read is sharper: if you want merge-on-read on Snowflake-managed v2, you must say so.
Here is the minimum table-level change:
ALTER ICEBERG TABLE lake_db.public.events
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'ENABLED';And here is the safer default pattern for a database with mixed tables:
ALTER DATABASE lake_db
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'AUTO';
ALTER ICEBERG TABLE lake_db.public.hot_events
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'ENABLED';
ALTER ICEBERG TABLE lake_db.public.reader_sensitive_events
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'DISABLED';The parameter is case-insensitive, and the most specific setting wins. A table setting beats a schema setting, which beats a database setting, which beats the account setting. Snowflake documents the same syntax on CREATE ICEBERG TABLE, where the parameter defaults to AUTO and can be set when the table is created in Snowflake as the Iceberg catalog.
CREATE ICEBERG TABLE lake_db.public.events (
event_id STRING,
event_ts TIMESTAMP_NTZ,
customer_id STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'lake_volume'
BASE_LOCATION = 'events'
ICEBERG_VERSION = 3
ICEBERG_MERGE_ON_READ_BEHAVIOR = 'AUTO';The gotcha is scope. ICEBERG_MERGE_ON_READ_BEHAVIOR only controls writes that Snowflake performs. If Spark, Flink, Trino, or another engine writes the same Iceberg table, that engine uses Iceberg table properties such as write.delete.mode, write.update.mode, and write.merge.mode. Snowflake says it does not use those properties to choose the Snowflake write method.
How does AUTO decide between merge-on-read and copy-on-write?
The new setting is really a compatibility switch disguised as a performance knob.
| Table case | AUTO behavior | File type Snowflake may write | Why you should care |
|---|---|---|---|
| Snowflake-managed Iceberg v2 | Copy-on-write | Rewritten data files | Safest for readers that do not handle positional deletes |
| Snowflake-managed Iceberg v3 | Merge-on-read | Deletion vectors when conditions are met | Better fit for frequent row-level changes |
| Externally managed Iceberg v2 | Merge-on-read | Positional delete files | Snowflake follows an external-lake pattern |
| Externally managed Iceberg v3 | Merge-on-read | Deletion vectors when conditions are met | The cleanest path if every engine supports v3 |
Do not read ENABLED as a promise that Snowflake will always write only delete files. Even when the setting resolves to merge-on-read, Snowflake still applies per-file heuristics. The docs say Snowflake writes a deletion vector only if fewer than approximately 5 percent of rows in a data file are deleted, and only when the file is larger than about 1.6 MB. If at least 5 percent of rows are deleted, Snowflake rewrites the file with copy-on-write.
That is good engineering. A delete file for half a file is not clever. It is a future read tax with a tiny hat.
The practical test is simple. If your workload deletes or updates a small share of rows across large files, merge-on-read can save write work. If your workload regularly rewrites large chunks of a partition, copy-on-write may be simpler and faster for downstream reads.
You can inspect the effective parameter before changing anything:
SHOW PARAMETERS LIKE 'ICEBERG_MERGE_ON_READ_BEHAVIOR'
IN TABLE lake_db.public.events;And you can reset a table override back to inherited behavior:
ALTER ICEBERG TABLE lake_db.public.events
UNSET ICEBERG_MERGE_ON_READ_BEHAVIOR;This matters during migrations. The old boolean ENABLE_ICEBERG_MERGE_ON_READ is deprecated. Snowflake says existing legacy settings are still honored when the new parameter is at AUTO, but the legacy setting is ignored when the new parameter is explicitly ENABLED or DISABLED in the new migration guidance.
-- Before
ALTER ICEBERG TABLE lake_db.public.events
SET ENABLE_ICEBERG_MERGE_ON_READ = TRUE;
-- After
ALTER ICEBERG TABLE lake_db.public.events
UNSET ENABLE_ICEBERG_MERGE_ON_READ;
ALTER ICEBERG TABLE lake_db.public.events
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'ENABLED';The non-obvious migration trap is Snowflake-managed v2. Setting the legacy boolean to TRUE does not force merge-on-read there when the new parameter is still AUTO. To force that case, use the new parameter explicitly.
Where can this move your Snowflake bill?
The parameter itself is not a new metered service. The cost shows up through the work it changes: warehouse DML, reader queries, storage optimization, and sometimes external storage requests.
For Snowflake-issued DML, your warehouse still pays for the UPDATE, DELETE, or MERGE. Snowflake's compute cost docs state that virtual warehouses consume credits while executing queries, loading data, and performing other DML operations in warehouse compute. Merge-on-read can reduce the amount of data rewritten during a small update, but it may add work later when readers have to merge delete files with data files.
Start by measuring DML shape, not arguing about lakehouse philosophy in a meeting room.
SELECT
query_id,
warehouse_name,
query_type,
rows_updated,
rows_deleted,
total_elapsed_time / 1000 AS seconds
FROM snowflake.account_usage.query_history
WHERE start_time >= DATEADD(day, -7, CURRENT_TIMESTAMP())
AND query_type IN ('UPDATE', 'DELETE', 'MERGE')
AND query_text ILIKE '%lake_db.public.events%'
ORDER BY start_time DESC;QUERY_HISTORY keeps 365 days of query data and includes rows_updated and rows_deleted, according to Snowflake's Account Usage reference. Pair that with warehouse metering if you need dollar allocation, but do not pretend one query history row gives perfect per-table cost attribution in a shared warehouse.
The second cost surface is compaction. Merge-on-read creates read-side debt. You pay it down by compacting files and cleaning up delete files. Snowflake's Iceberg management docs say table optimization features include data compaction, manifest compaction, and snapshot expiry. Data compaction is enabled by default for Snowflake-managed Iceberg tables, and Snowflake exposes billed compaction credits in ICEBERG_STORAGE_OPTIMIZATION_HISTORY.
SELECT
database_name,
schema_name,
table_name,
SUM(credits_used) AS compaction_credits,
SUM(num_bytes_scanned) / POW(1024, 4) AS tib_scanned,
SUM(num_rows_written) AS rows_compacted
FROM snowflake.account_usage.iceberg_storage_optimization_history
WHERE start_time >= DATEADD(day, -30, CURRENT_TIMESTAMP())
GROUP BY 1, 2, 3
ORDER BY compaction_credits DESC;That view has up to 2 hours of latency and retains 365 days of history, and Snowflake says the CREDITS_USED column reports credits billed for data compaction in the Iceberg storage optimization view. If this number rises after enabling merge-on-read, you did not get a free lunch. You moved work from the DML path into maintenance.
Snowflake storage adds one more wrinkle. For Iceberg tables using Snowflake storage, Snowflake says compaction is bundled with no separate compaction charge while the table is written only by Snowflake; once an external engine performs DML or DDL through the Iceberg REST Catalog on or after May 21, 2026, compaction charges can appear in the same history view in the storage cost documentation. That is the kind of clause that turns a clean architecture diagram into a FinOps ticket.
If external engines read Snowflake storage through Horizon Catalog, watch request counts too:
SELECT
operation_type,
SUM(count) AS requests
FROM snowflake.account_usage.storage_request_history
WHERE start_time >= DATEADD(day, -30, CURRENT_TIMESTAMP())
GROUP BY 1
ORDER BY requests DESC;Snowflake says STORAGE_REQUEST_HISTORY tracks Class 1 operations such as PUT, COPY, POST, PATCH, and LIST, plus Class 2 operations such as GET and SELECT, with up to 6 hours of latency in the storage request view. For Snowflake query engine access, that view is not the bill meter. For external engines, it can explain why an open table suddenly feels less open and more metered.
Who should be allowed to flip the switch?
Treat this like a production performance setting, not a casual table option. Snowflake's ALTER ICEBERG TABLE docs say the executing role needs OWNERSHIP on the Iceberg table, plus USAGE on the external volume and catalog integration where applicable in the access control requirements.
That should push you toward a small owner role, not a broad data engineering super-role.
GRANT USAGE ON DATABASE lake_db TO ROLE iceberg_dml_admin;
GRANT USAGE ON SCHEMA lake_db.public TO ROLE iceberg_dml_admin;
GRANT OWNERSHIP ON ICEBERG TABLE lake_db.public.events
TO ROLE iceberg_dml_admin
COPY CURRENT GRANTS;Then make the actual mode changes through reviewed migrations:
USE ROLE iceberg_dml_admin;
ALTER ICEBERG TABLE lake_db.public.events
SET ICEBERG_MERGE_ON_READ_BEHAVIOR = 'DISABLED';The governance point is boring because it is correct: table owners can change read/write cost shape for every downstream consumer. If one team optimizes its nightly MERGE and slows a dozen BI reads, you have not optimized the platform. You have moved pain to a group with worse dashboards.
When should you enable merge-on-read, and when should you refuse it?
Use AUTO as the default until you can name a workload that needs something else. It is conservative in exactly one place: Snowflake-managed v2. That is the place where reader compatibility is most likely to bite.
Enable merge-on-read explicitly when three conditions hold:
- The table sees frequent
UPDATE,DELETE, orMERGEoperations that touch a small share of rows per data file. - Your readers support the relevant Iceberg delete mechanism, positional deletes for v2 or deletion vectors for v3.
- You are prepared to monitor compaction through
ICEBERG_STORAGE_OPTIMIZATION_HISTORYfor at least 30 days.
Disable it when reads dominate and latency matters more than DML speed. Also disable it when you share tables with engines that do not support Iceberg v3 deletion vectors or v2 positional delete files. Snowflake explicitly recommends DISABLED for Iceberg v3 deletion vector compatibility gaps, and that advice is worth taking before your lake turns into a support matrix.
For a table with heavy batch replacements, copy-on-write can be the cleaner model. If each run updates 20 percent of a partition, merge-on-read will not save you from rewriting anyway because Snowflake's heuristic flips to copy-on-write at about 5 percent of rows deleted in a file. You might still see delete files for smaller files or smaller touches, but the broad pattern is not a match.
My default rollout would be boring on purpose:
- Leave the account at
AUTO. - Pick 3 to 5 high-DML Iceberg tables.
- Confirm reader compatibility by engine and version.
- Set
ENABLEDonly at the table level. - Compare 30 days of DML duration, warehouse credits, read latency, and compaction credits.
That last step is the moat. Anyone can flip a parameter. The team that wins is the one that proves where the work went.
What is the sensible bet?
ICEBERG_MERGE_ON_READ_BEHAVIOR is a good Snowflake feature because it admits the lakehouse truth: open table formats do not remove trade-offs. They expose them.
The right answer is not universal merge-on-read. The right answer is explicit ownership of write speed, read latency, compatibility, and compaction cost at the table boundary. Snowflake has finally given that boundary a named switch.
Use it like a scalpel. Your bill will know if you use it like a broom.
Sources
- Snowflake Documentation: 10.20 Release Notes
- Snowflake Documentation: Manage Apache Iceberg tables
- Snowflake Documentation: CREATE ICEBERG TABLE, Snowflake as the Iceberg catalog
- Snowflake Documentation: ALTER ICEBERG TABLE
- Snowflake Documentation: Understanding compute cost
- Snowflake Documentation: ICEBERG_STORAGE_OPTIMIZATION_HISTORY view
- Snowflake Documentation: STORAGE_REQUEST_HISTORY view
- Snowflake Documentation: QUERY_HISTORY view