A data agent that can build pipelines is useful. A data agent that knows which tables matter, which pipelines already touch them, and when to stop and ask you before firing a tool call is the version you can let near production.
Matillion Context Engine is the new public preview layer that gives Maia AI Agents knowledge graphs, crawlers, and task context, with Mission Control adding a 10 task in-progress cap around agent work.
Matillion shipped Context Engine and Mission Control together because the old problem with AI assistants in data engineering is not syntax. It is context. Maia can already build orchestration and transformation pipelines, query warehouse data, sample pipeline data, manage files, and commit or push changes inside the Data Productivity Cloud, according to Matillion's Maia AI Agents overview. Context Engine gives those agents a living map of your warehouse metadata, pipeline execution history, business language, and project scope. Mission Control gives you a kanban board where that work becomes task shaped instead of chat shaped.
If you are still getting oriented around the platform, start with our guide to Matillion's Data Productivity Cloud for builders. This piece assumes you already build in Maia or Designer and now need to decide where Context Engine belongs in your operating model.
What did Matillion actually ship in Context Engine?
Context Engine is in public preview, and the important object is the knowledge graph. Matillion describes it as a way to capture the structure, relationships, and meaning of your data, then let Maia use that graph when it works on a task in Mission Control or chat. In plain builder terms: it is metadata grounding for Maia, scoped to projects and fed by crawlers, not another Markdown rules file with a nicer name.
The Context Engine dashboard sits under the AI Agents icon in the left navigation. It lists knowledge graphs you can access, lets you filter by project, and supports search by name or description. From there, an Admin or Super Admin can add a knowledge graph, choose whether it is Public or Restricted, and give it a name and description, as Matillion's Context Engine documentation spells out.
That Public or Restricted choice is not cosmetic. A public knowledge graph is available in all projects. A restricted graph is available only to selected projects. Matillion explicitly warns that public graphs should not ingest sensitive data that should not be available to all projects. That is the kind of sentence you should read twice before turning a sales operations graph into a company wide default.
Once a graph exists, it has three important tabs:
- Crawlers, where you add and monitor crawlers that populate the graph.
- Projects, where you manage which projects can use a restricted graph.
- Access, where you add users who can manage the graph.
The crawler model is refreshingly concrete. Matillion supports 2 crawler types: Warehouse data crawlers and Pipeline execution crawlers. Warehouse data crawlers harvest warehouses and structured sources supported through connectors. Pipeline execution crawlers harvest executions for a chosen project and environment, giving Maia operational context about how work actually flows.
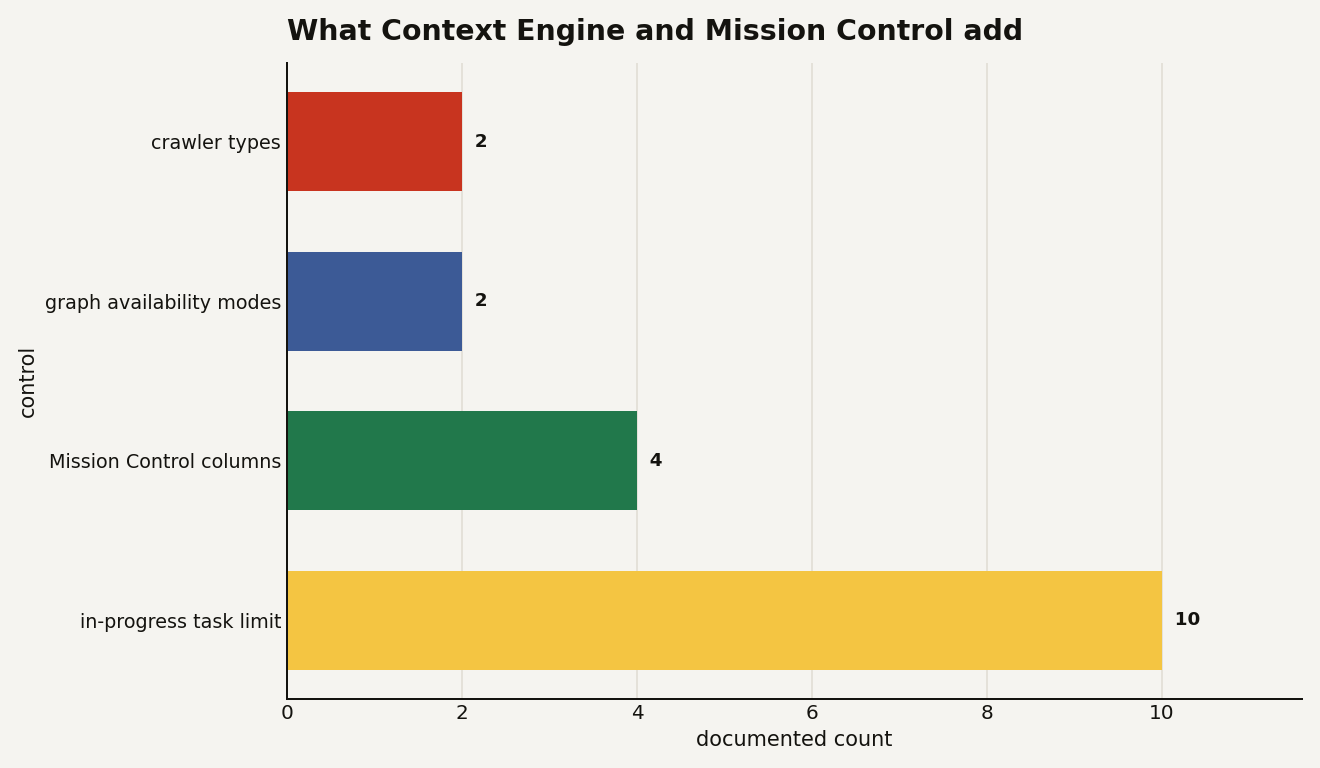
As the chart shows, the launch is not just a new button. Context Engine and Mission Control introduce 2 crawler types, 2 graph availability modes, 4 task board columns, and a 10 task in-progress limit. Those numbers matter because they turn agent context into something you can scope, schedule, and govern.
Crawler setup has a few warehouse specific details. For Warehouse data crawlers, the data selection step depends on the target: Snowflake uses databases and schemas, Databricks uses catalog and schemas, and Amazon Redshift uses schemas. You can schedule crawler runs with Standard settings or Advanced schedule settings, including a cron expression. You can also run a crawler on demand with Run now.
The crawler status model gives you the minimum you need to operate it: Successful, Initializing, Extracting, Pending, Paused, and Failed. You can inspect the latest crawl or crawl history, including status, start time, end time, and duration. That is not observability nirvana, but it is enough to answer the first operational question: did the graph refresh before Maia used it?
How does Maia use the graph when it starts a task?
The graph becomes useful when you attach it to Maia's work. In Mission Control, the New task dialog includes Project, Branch, Environment, Knowledge Graph, and Prompt fields. The Knowledge Graph drop-down selects the graph Maia will use to inform that task, according to Matillion's Mission Control guide.
The same idea appears in the Agent Tasks API as graphId. That is the cleanest signal that Context Engine is not just a UI feature. You can pass graph context into programmatic agent work.
curl --request POST \
--url "$BASE_URL/v1/ai/agents/tasks" \
--header "Authorization: Bearer $MATILLION_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"message": "Plan a pipeline for daily net revenue by region using our governed sales model.",
"agentConfig": {
"name": "data_engineer_agent",
"mode": "PLAN",
"projectId": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"sourceBranchName": "main",
"environmentName": "development",
"targetBranchName": "feature/revenue-region-plan",
"graphId": "finance-analytics-graph"
}
}'Matillion's Agent Tasks API guide defines name as currently always data_engineer_agent, mode as either ACT or PLAN, and graphId as the ID of a Knowledge Layer service graph. Use PLAN when you want the graph to shape a design without letting Maia make changes yet. Use ACT only when you are comfortable with the branch, environment, and permissions.
That branch point matters. Each task works in isolation on its own branch when you create work through the API. Matillion also says Agent Tasks API work runs under the identity of the user associated with the API key, and changes are not automatically visible to other project users unless Maia commits and pushes to the target branch. Good. Agent work should leave a diff, not a mystery.
There is one practical catch: the docs say these endpoints currently work only with Matillion-hosted and GitHub projects. If your team is standardized on another Git provider, test the path before you design a team process around it.
How is Context Engine different from context files?
Context files still matter. They are Markdown files that Maia always reads from .matillion/maia/rules/, and Matillion enforces a 12,000 character limit across all Markdown context files in that directory. They are the right place for rules: naming conventions, design standards, business glossary shortcuts, and team preferences.
Context Engine is for the map.
Here is the split that should guide your setup:
| Mechanism | Best use | Concrete limit or setting |
|---|---|---|
| Context files | Always applied rules for a project | Stored under .matillion/maia/rules/ with a 12,000 character total limit |
| Additional project files | Detailed standards Maia can reference when instructed | Stored outside .matillion/... and referenced from a context file |
| Context Engine knowledge graphs | Warehouse metadata, relationships, semantics, and execution context | Fed by Warehouse data and Pipeline execution crawlers |
The best setup uses both. Put hard rules in context files: table prefixes, environment constraints, source of truth definitions, and review expectations. Put metadata and process reality in Context Engine: schemas, columns, tags, warehouse structures, and pipeline execution history.
Do not stuff everything into the graph because it feels newer. If a rule is small, stable, and mandatory, put it in a context file. If the context changes as pipelines run and schemas evolve, put it in the graph.
What does it cost, and where can it surprise the bill?
Matillion's public docs do not publish a separate Context Engine credit rate in the pages reviewed for this guide. That absence is its own buying signal. You should not treat public preview as free forever, and you should not assume every action has a visible line item until you validate it with your account data.
There are 3 cost surfaces to watch.
First, crawler frequency. A Warehouse data crawler connects to data warehouse structures such as Snowflake databases and schemas, Databricks catalogs and schemas, or Redshift schemas. Even if Matillion does not show a separate Context Engine meter in the public docs, that crawler is still operating against systems you pay to run. Start with a low frequency schedule, then increase it only for domains where schema drift or metadata freshness affects real delivery.
Second, agent work. Maia can validate and run pipelines, query the data warehouse, sample component output, commit changes, and push branches. Mission Control lets up to 10 tasks sit in the In progress column at once. Ten autonomous tasks pointed at a development warehouse can be a productivity win. Ten autonomous tasks repeatedly sampling, running, and revising pipelines can also turn a quiet sandbox into a noisy bill.
Third, preapproved tools. The Agent Tasks API supports grantedPermissions, and the Mission Control UI has Ask permission and Bypass permissions modes. Matillion recommends Ask permission as the default and Bypass permissions only for trusted hands-off runs in scoped environments. That is not conservative vendor boilerplate. It is the right default for anyone who has ever watched a retry loop discover money.
For cost monitoring, Matillion's MCP server exposes Consumption tools, including get-consumption for flat-rated products and get-consumption-etl-users for ETL users, and it can help analyze credit consumption patterns through an AI assistant via the MCP server documentation. Use that for investigation, but do not let an assistant be your only FinOps control. Pull consumption on a schedule, tag task branches clearly, and compare before and after you enable crawler schedules.
A sane rollout looks like this:
- Create one restricted knowledge graph for a single analytics domain.
- Add one Warehouse data crawler and one Pipeline execution crawler.
- Schedule crawls outside peak warehouse windows.
- Run Maia tasks in
PLANmode first. - Keep Ask permission on until you know which tools Maia calls repeatedly.
- Review consumption and warehouse activity after one week.
The boring version wins.
When should you use Mission Control with Context Engine?
Use Mission Control when the work has a deliverable. A chat is fine for asking Maia to explain a Table Input component or suggest a naming convention. A Mission Control task is better when you want Maia to design a pipeline, modify project files, create a connector, analyze a failure, or work from a PDF spec.
The task board has 4 columns: Backlog, In progress, Needs attention, and Completed. That sounds simple because it is. The useful part is that each task has its own chat interface, and you can switch between tasks without losing context. For a data team, that maps better to real work than one endless assistant thread.
Mission Control also adds attachments. You can attach images and PDFs to a task prompt, then reference them with @filename. Matillion says images can include diagrams, screenshots, mockups, and whiteboard photos, while PDFs can include specs, requirements documents, and reports. Text files are not supported as attachments because Maia can already read project text files.
Use that for pipeline triage. A screenshot of a broken canvas plus a pipeline execution crawler is exactly the kind of mixed context that a human engineer would ask for. The difference is Maia can now carry that context into a branch and produce work you can review.
Do not use Mission Control as a merge gate. Matillion says completing a task does not make changes visible on other branches. You still need to commit, push, and merge. Maia cannot merge changes, which is a good boundary. Keep code review, pipeline tests, and environment promotion in your normal process.
What would I do first in a real Matillion team?
Start with one graph per domain, not one graph per company. Finance, customer, product, and operations usually have different semantics and different blast radiuses. A public all-company graph sounds convenient until it contains restricted HR tables or ambiguous definitions that poison every prompt.
Then tune freshness by risk. Operational pipeline execution context can go stale quickly if you are actively refactoring. Warehouse schema metadata may not need hourly crawls if your governed marts change weekly. Context Engine supports any number of Warehouse data and Pipeline execution crawlers on a graph, so separate them by source and schedule rather than creating one giant crawler that nobody wants to touch.
Use PLAN mode as your default for the first few tasks. Ask Maia to propose pipeline structure, sources, joins, variable usage, and tests while grounded in the selected graph. Once the plans look sane, let a narrow ACT task implement on a feature branch.
Most of all, measure whether Context Engine reduces clarification loops. The win is not that Maia can produce more pipeline files. The win is fewer wrong assumptions about customer_id, fewer duplicated staging models, fewer prompts that repeat your business glossary, and fewer reviews that start with: who told the agent to use that table?
If Context Engine does that, it earns a place in the stack. If it becomes another metadata garden that nobody prunes, Maia will learn your mess at machine speed.